






ChatGPT 是否能真正“记住”你的话是一个值得探讨的问题。
Django框架的杰出贡献者之一,知名开发者Simon Willison近期在博客上分享了他的洞见。文章的核心观点是,尽管许多大型语言模型(LLM)在表面上似乎展现出了记忆能力,但究其本质,它们实际上是无状态函数。这一观点引发了关于LLM工作机制和特性的深入讨论。

Mozilla和Firefox的联合创始人,同时也是JavaScript的发明者Brendan Eich也在推特上对这篇博客文章给予了高度的赞誉。
从计算机科学的角度来看,大型语言模型(LLM)的推理过程实际上更适合被视作无状态函数调用的序列。这意味着,当给定一段输入文本时,LLM会输出相应的响应,而不会保持任何与先前对话的“记忆”状态。
然而,对于使用过ChatGPT或Gemini等先进AI对话系统的用户来说,他们可能会明显感觉到这些模型似乎能够记住之前的对话内容,并据此进行回应,仿佛它们具备了某种记忆能力。
但值得注意的是,这种“记忆”的表象并非源自模型本身固有的记忆机制。事实上,当用户提出一个问题时,模型所接收到的提示中包含了之前所有的对话内容。这些包含历史对话的提示,我们通常称之为“上下文”。正是这个上下文信息,使得模型能够产生连贯的回应,给人一种模型具有记忆能力的错觉。

如果不为大型语言模型(LLM)提供上下文信息,它将无法知晓之前讨论的内容。因此,每当用户重新打开一个对话界面时,对于LLM来说,这就像是面对一个全新的文本序列,完全独立于之前与任何用户的对话历史。
从另一方面来看,这种“失忆”特性也有其积极之处。例如,当模型产生不准确的回应或拒绝回答合理问题时,用户可以尝试重置对话窗口,这有可能使模型的输出重新回归正轨。
这也解释了为什么LLM的上下文长度是一个关键的考量因素。当对话变得过长,以至于超出了模型的上下文窗口容量时,最早部分的对话就会被从提示中移除,这就如同模型“遗忘”了那些信息。
Andrej Karpathy将上下文窗口形象地描述为“LLM工作记忆的有限宝贵资源”。然而,为了满足实际产品的使用需求,有多种方法可以为LLM提供外置的记忆能力。
将先前的对话作为提示,与当前问题一同输入给LLM,是最直接的方法之一。但这种方法仍属于“短期记忆”,并且扩展模型上下文长度的成本通常很高。例如,GPT-4的免费版支持8k的上下文长度,而付费版可以达到128k,尽管这已比之前的32k提升了3倍,但仍不足以完整保存单个网页的原始HTML内容。

另一种策略是递归地总结先前的对话内容,并将历史对话的摘要作为LLM的提示。虽然这种方法可能会丢失一些细节,但相较于直接截断的方法,它能在更大程度上保留内容的完整性。
另一种为LLM添加“长期记忆”的方法是外接矢量数据库。在对话过程中,系统首先从数据库中检索相关的内容,然后将这些内容添加到当前的上下文窗口中,这种方法被称为检索增强生成(RAG)。然而,如果数据库内容过于庞大,检索过程可能会增加模型的响应延迟。
在实际开发中,为了平衡成本和性能,以及长期和短期记忆的需求,检索和摘要这两种手段通常会被搭配使用。
虽然LLM的推理过程可以看作是无状态函数的调用,但其训练过程并非如此,否则它将无法从语料库中学习到任何知识。然而,关于LLM的记忆机制,我们存在分歧:它是否只是“机械”地复制了训练数据,还是更类似于人类的学习过程,通过理解和概括将数据内容集成在模型参数中?
DeepMind近期发表的一篇论文或许能为我们从另一个角度揭示这个问题。

为了测试LLM是否能在某种程度上“复现”其训练数据,研究者们使用了与训练语料相似的prompt来攻击这些模型。然而,对于像Falcon、Llama、Mistral这样的常用半开放LLM,以及GPT系列,由于它们并未公开训练数据,判断模型输出是否源自训练集变得尤为困难。
为了克服这一挑战,论文中采用了一种创新的方法。研究者首先从RefinedWeb、RedPajama、Pile等常用的LLM预训练数据集中选取了9TB的文本作为辅助数据集。接下来,他们提出了一个假设:如果模型输出的文本序列足够长,信息熵足够高,且这段文本与辅助数据集中的内容有重叠,那么可以合理推断模型在训练过程中很可能接触过这条数据。
需要指出的是,这种方法可能存在假阴性,因为辅助数据集无法涵盖所有模型的训练数据。但这种方法几乎不会出现假阳性,因此所得结果可以作为模型“复现”训练内容比例的下界估计。
通过这种方法,研究者们发现所有的模型在某种程度上都能逐字逐句地输出训练数据,尽管这种能力在不同模型间存在差异,表现为输出训练数据的概率有所不同。
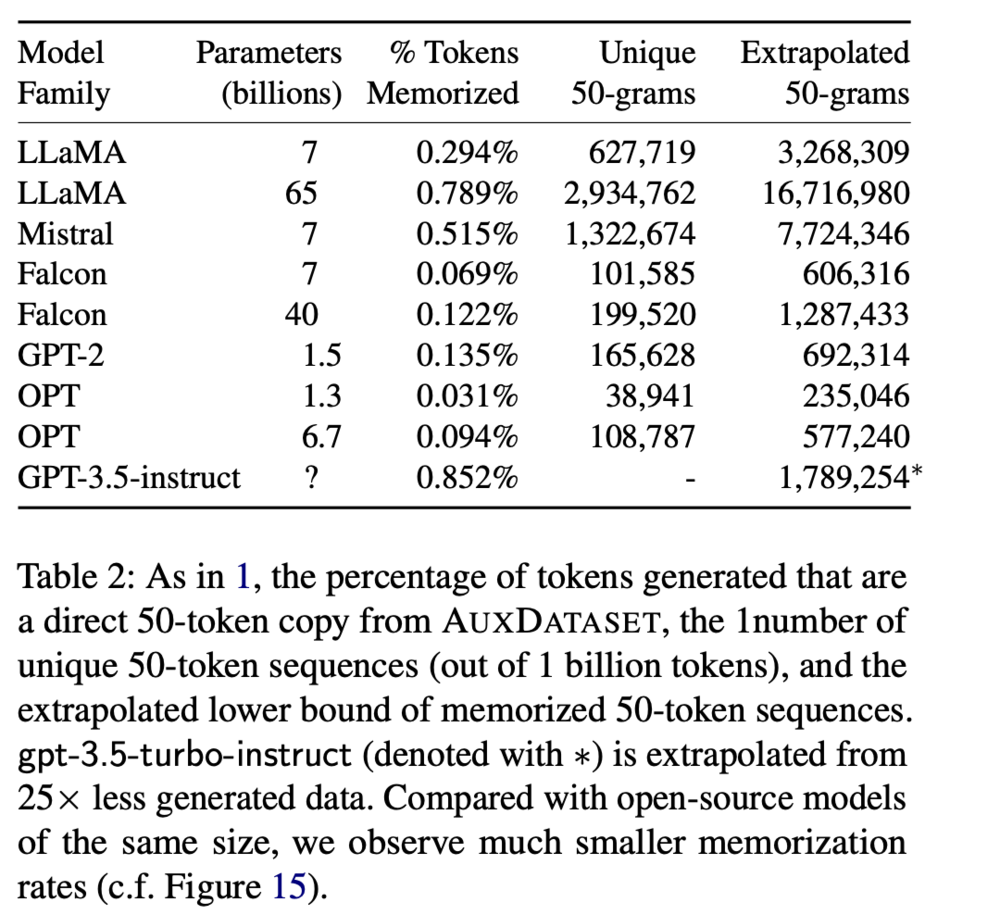
分析结果显示,模型的参数量与其“记忆”能力似乎存在一定的正相关性。具体而言,拥有更大参数量的模型似乎能够记住更多的内容,并因此在输出中更有可能重现训练数据。
不同系列的模型在记忆能力上展现出显著的差异。例如,拥有7B参数的Mistral模型与Falcon相比,其输出中原样出现训练数据的概率高达近10倍之多。
然而,这种差异可能由多种因素造成。一方面,它可能反映了不同模型在记忆能力上的本质差异;另一方面,也可能是由于辅助数据集的选择和构建过程中存在的偏差所致。
有趣的是,当使用持续输出某个单词的prompt时,某些特定的单词更容易触发模型输出训练数据。这一发现为我们理解模型的记忆机制提供了新的视角,也揭示了模型在特定情境下可能存在的“记忆偏好”。

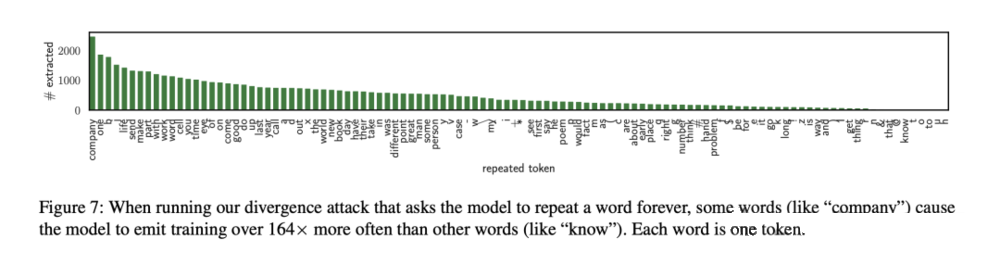
在测试中,“company”这一单词被揭示为最有可能触发模型输出训练数据的词汇之一。作者强调,从安全性的视角来看,这一发现表明对齐过程并未完全掩盖模型的记忆痕迹,而这些可提取的训练数据片段可能引发版权纠纷和隐私泄露的严重问题。
然而,从另一个角度审视,这也证明了训练数据中的一定比例被模型以无损压缩的形式存储在其参数之中。这揭示出模型的记忆方式确实带有某种“机械化”的特质。
进一步思考,我们不禁要问:如果改进LLM的记忆机制,使其能够以更概括、更抽象的方式存储训练数据,是否有可能带来模型性能的持续提升?这样的改进不仅能够降低隐私泄露的风险,还可能推动LLM在更广泛的领域展现出更为强大的能力。
ChatGPT
人工智能
AI
小程序开发
阅读排行
-
1. 微信支付商户申请接入流程
微信支付,是微信向有出售物品/提供服务需求的商家提供推广销售、支付收款、经营分析的整套解决方案,包括多种支付方式,如JSAPI支付、小程序支付、APP支付H5支付等支付方式接入。
查看详情 -
2. 浙江省同区域公司地址变更详细流程
提前准备好所有需要的资料,包含:房屋租赁合同、房产证、营业执照正副本、代理人身份证正反面、承诺书(由于我们公司其中一区域已有注册另外一公司,所以必须需要承诺书)
查看详情 -
3. 阿里云域名ICP网络备案流程
根据《互联网信息服务管理办法》以及《非经营性互联网信息服务备案管理办法》,国家对非经营性互联网信息服务实行备案制度,对经营性互联网信息服务实行许可制度。
查看详情 -
4. 微信小程序申请注册流程
微信小程序注册流程与微信公众号较为相似,同时微信小程序支持通过已认证的微信公众号进行注册申请,无需进行单独认证即可使用,同一个已认证微信公众号可同时绑定注册多个小程序。
查看详情 -
5. Higress推出全新 WebAssembly (Wasm) 运行时,实现显著性能飞跃
Higress切换到WAMR运行时,Wasm插件性能显著增强Higress近日宣布,其Wasm插件的运行时已从V8成功切换到WebAssemblyMicroRuntime(WAMR),并在开启AOT(Ahead-Of-Time)编译模式后,实现了显著的性能提升。据测试数据显示,大部分插件的平均性能提升了约50%,而对于逻辑复杂的插件,其性能甚至实现了翻倍增长。
查看详情
